This section will trace the development of TCP/IP through specific enhancements made to the Transmission Control Protocol. Version numbers of the networking code released by Berkeley Software Distribution will be used as milestones in TCP/IP's development, as most implementations of UNIX have tracked Berkeley's improvements. Figure 3.7 shows TCP/IP's timeline and the revision increments that will be considered here.
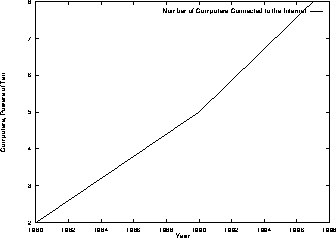
As Internet usage increased exponentially, so did the congestion
problems. Comer relates the exponentiality of the expansion in chart
form, the numbers are reproduced here as the logarithmic plot in
figure 3.8![]() . This growth manifested itself as periods
of lowered bandwidth and increased delays, and caused researchers at
Lawrence Berkeley Laboratories (LBL) to question the mechanism
employed by the current implementation of TCP to combat congestion.
Most of the improvements made to TCP were instigated by this group,
led by Van Jacobson, who has achieved nearly deity status in
networking circles. As Jacobson and Michael Karels relate in
Congestion Avoidance and Control:
. This growth manifested itself as periods
of lowered bandwidth and increased delays, and caused researchers at
Lawrence Berkeley Laboratories (LBL) to question the mechanism
employed by the current implementation of TCP to combat congestion.
Most of the improvements made to TCP were instigated by this group,
led by Van Jacobson, who has achieved nearly deity status in
networking circles. As Jacobson and Michael Karels relate in
Congestion Avoidance and Control:
In October of '86, the Internet had the first of what became a series of 'congestion collapses'. During this period, the data throughput from LBL [Lawrence Berkeley Laboratories] to UC Berkeley (sites separated by 400 yards and two IMP hops) dropped from 32 Kbps to 40bps. We were fascinated by this sudden factor-of-thousand drop in bandwidth and embarked on an investigation of why things had gotten so bad. In particular, we wondered if the 4.3bsd (Berkeley UNIX) TCP was mis-behaving or if it could be tuned to work better under abysmal network conditions. The answer to both of these questions was ``yes''.[19]
The specific improvements made to TCP that are important within the context of this document are listed in chronological order in table 3.2.
Table 3.2: Improvements in TCP
The Transmission Control Protocol and the Internet Protocol in their earliest incarnations are defined in two Internet Request For Comments (RFCs), RFC793[41] and RFC791[40], respectively. From the introduction of RFC793, the Transmission Control Protocol:
The Transmission Control Protocol (TCP) is intended for use as a highly reliable host-to-host protocol between hosts in packet-switched computer communication networks, and in interconnected systems of such networks.[41, p.1,]
And, more specifically:
TCP is a connection-oriented, end-to-end reliable protocol designed to fit into a layered hierarchy of protocols which support multi-network applications. The TCP provides for reliable inter-process communication between pairs of processes in host computers attached to distinct but interconnected computer communication networks. Very few assumptions are made as to the reliability of the communication protocols below the TCP layer. TCP assumes it can obtain a simple, potentially unreliable datagram service from the lower level protocols. In principle, the TCP should be able to operate above a wide spectrum of communication systems ranging from hard-wired connections to packet-switched or circuit-switched networks.[41, p.1,]
TCP uses layering to hide the details of its reliable, stream-based service from the application layer. It can effectively create a virtual point to point link between two separate processes, either running on the same machine or on separate machines, connected through a physical network. This connection is so reliable that it is often treated, from a programming perspective, as if it were between an application and a file residing on a local disk drive.
TCP works at the byte-level of data. It divides an incoming data stream into packets called segments; similar to datagrams in that each segment is packaged with a full header that is interpretable by TCP, but subtly different in that segments do not create discernible record boundaries, they merely represent sections of a continuous stream of data.
Reliability is insured by a sliding-window acknowledgement and retransmission mechanism. All data sent by TCP must be acknowledged by the receiver at the other end of the connection. TCP maintains a variable-sized window of data that is allowed to exist unacknowledged in the network at any given time. If this limit is reached, no data is sent until an acknowledgement is received. If no data has been acknowledged in a certain amount of time, as detected by the expiration of the Retransmission Time Out (RTO) timer, TCP assumes that the data has become somehow lost or destroyed, and retransmits all of the data in the window.
The original method for calculating the RTO time was rather crude, and could adapt to network loads of at most 30% (equations 3.1, 3.2 and 3.3):
In the above equations, ![]() is calculated by passing the
measured round trip times (RTT) through what is essentially a low pass
filter, rejecting quick changes in the measured round trip times.
With
is calculated by passing the
measured round trip times (RTT) through what is essentially a low pass
filter, rejecting quick changes in the measured round trip times.
With ![]() usually defaulting to 0.9 and
usually defaulting to 0.9 and ![]() taking its
suggested value of 2, 4.2BSD's RTO calculation mechanism left much
to be desired during the congestion collapses of the mid 1980's.
taking its
suggested value of 2, 4.2BSD's RTO calculation mechanism left much
to be desired during the congestion collapses of the mid 1980's.
4.3BSD Tahoe grew out of optimizations suggested in Jacobson's Congestion Avoidance and Control.[19] This paper set the standard for protocol optimization, and influenced a great deal of subsequent internetworking protocols, including the one developed as part of this MQP. The fundamental points are itemized below:
Much of the time, earlier implementations of TCP would end up initially ``shocking'' a network by sending too much data right off the start. Taking a cue from a standard practice in electrical equipment design where the in-rush of electrical current into a device is desirably limited and slowly increased during a turn-on phase, Jacobson and his fellow researchers created a slow-start mode for TCP that exponentially increases the size of a congestion window. The exponential increase was enough to let TCP feel-out a connection's bandwidth and delay statistics while allowing the network to acclimate itself to the increase in load. Figure 3.2.2 shows Tahoe's slow-start mechanism theoretical throughput vs. time in comparison to 4.2BSD's.
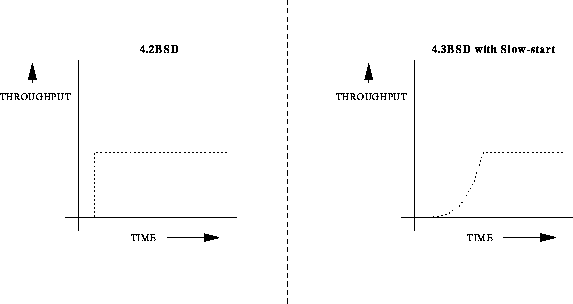
Figure 3.9: The slow-start algorithm of 4.3BSD Tahoe TCP
Jacobson's group also made changes to the Retransmission Time Out
(RTO) estimation algorithms. The modified algorithm takes RTT
variance ( ![]() ) into account instead of using a
constant
) into account instead of using a
constant ![]() value as indicated in the previous section (EQ:
3.3):
value as indicated in the previous section (EQ:
3.3):
The new RTO estimator is capable of adapting to much greater loads. In addition, the entire algorithm was tweaked to utilize integer arithmetic based on computation with scaled powers of two, instead of fractional floating point arithmetic, further reducing CPU load.
Quite often, TCP implementations would worsen network congestion due to multiple, successive retransmits. The RTO estimator is only updated upon receipt of an acknowledgement; if data is continually lost due to high network loading, the data will be retransmitted at constant intervals. Phil Karn, in his implementation of TCP/IP for extremely low-bandwidth, high-delay amateur packet radio usage, developed a strategy that handles multiple retransmits with an exponential back-off of the RTO timer for each successive retransmit.
Tahoe offered a means of combating congestion through dynamically altering the size of the protocol's sliding window. The algorithm followed three simple rules:
The performance of 4.3BSD Tahoe was outstanding. In a Usenet news message, Jacobson expressed the details:
I don't know what would constitute an ``official'' confirmation but maybe I can put some rumors to bed. We have done a TCP that gets 8Mbps between Sun 3/50s (the lowest we've seen is 7Mbps, the highest 9Mbps - when using 100Ethernet exponential back-off makes throughput very sensitive to the competing traffic distribution.) The throughput limit seemed to be the Lance chip on the Sun - the CPU was showing 10-15time. I don't believe the idle time number (I want to really measure the idle time with a uprocessor analyzer) but the interactive response on the machines was pretty good even while they were shoving 1MB/s at each other so I know there was some CPU left over.[Article 167, comp.protocols.tcp-ip, March 1988][21]
4.3BSD Reno implements both fast recovery/retransmit and header prediction, improvements arguably specific to TCP/IP but bearing little relevance to other communications protocols. Study of these will be avoided here, since the design of this MQP's protocol isn't affected by either enhancement.
Internet Request For Comments number 1323 (RFC1323)[28] specified a set of extensions to TCP that attempt to extend its usability on networks with large bandwidth capability and long delay times. Below are listed the relevant suggested optimizations:
The optimizations are presented with the idea that TCP's performance relies on the product of the utilized bandwidth and the round trip delay time, yielding a measure of the amount of data present in the network at any given time. This calculation (equation 3.5) is elucidated in RFC1323:
TCP performance depends not upon the transfer rate itself, but rather upon the product of the transfer rate and the round-trip delay. This ``bandwidth*delay product'' measures the amount of data that would ``fill the pipe;'' it is the buffer space required at sender and receiver to obtain maximum throughput on the TCP connection over the path, i.e., the amount of unacknowledged data that TCP must handle in order to keep the pipeline full. TCP performance problems arise when the bandwidth*delay product is large. We refer to an Internet path operating in this region as a ``long, fat pipe,'' and a network containing this path as an ``LFN'' (pronounced ``elephan(t)''). [28, p.2,]
TCP currently uses a 16-bit unsigned integer in the header of each TCP
segment to communicate the size of the receive buffer to the sender.
With this limitation, the maximum amount of data allowed in the
network's buffers at any one time is 64KBytes; up until recently this
hasn't had any detrimental effect on TCP's performance. Even
utilizing the full bandwidth of a 10Mbps Ethernet, the round trip time
required to fill the window would be in excess of 50ms, an event
rarely witnessed on a LAN. However, recent advancements in
physical-layer networking technology have made gigabit throughput
rates realizable. In the case of a full-bandwidth, 1Gbps transfer
rate, TCP's window size would necessitate a round trip time no longer
than ![]() ; clearly, the effective bandwidth achievable with TCP
is theoretically limited by the round trip time delay as
; clearly, the effective bandwidth achievable with TCP
is theoretically limited by the round trip time delay as
![]() . Thus, with a low 1ms RTT, TCP's
ultimate achievable bandwidth is 524Kbps.
. Thus, with a low 1ms RTT, TCP's
ultimate achievable bandwidth is 524Kbps.
The TCP window scaling extends the window size to 32 bits, and is predicted to yield acceptable performance for quite some time into the future, tolerating a 34 second round trip time on a 1Gbps link.
Originally, the designers of TCP discarded the idea of per-sequence timestamps because of the compute power required to retrieve data from the system clock. The difficulty in obtaining accurate measurement of round trip time intervals necessary for the determination of the retransmission time was compounded by this lack of timestamps. These days, CPU power has grown to the point where time-stamping is cheap. The implementation of RTTM for TCP adds increased accuracy with very little impact on the compute time budget.
Links with large ![]() products utilizing the TCP
window scaling option could generate windows so large that there is
potential to wrap the 32-bit per-segment sequence number around while
data is still waiting in network queues. If this happened, two
different segments, both numbered zero, would exist on the
network at the same time, making proper acknowledgement impossible.
products utilizing the TCP
window scaling option could generate windows so large that there is
potential to wrap the 32-bit per-segment sequence number around while
data is still waiting in network queues. If this happened, two
different segments, both numbered zero, would exist on the
network at the same time, making proper acknowledgement impossible.
PAWS makes use of the new TCP timestamps to take both the sequence number and the departure time of segments into account, weeding out duplicate sequence numbers.
TCP Vegas
![]() is an implementation of TCP developed at the University of Arizona
from 4.3BSD Reno source code. It promises increased
throughput over that of the existing TCP implementations largely due
to its congestion anticipation mechanism. Vegas's
congestion anticipation algorithm dynamically varies the size of the
congestion window by monitoring the utilized bandwidth for small
changes. This method contrasts with Reno's congestion
avoidance mechanism that needs to create losses to vary the
congestion window size, Vegas attempts to predict
congestion.
is an implementation of TCP developed at the University of Arizona
from 4.3BSD Reno source code. It promises increased
throughput over that of the existing TCP implementations largely due
to its congestion anticipation mechanism. Vegas's
congestion anticipation algorithm dynamically varies the size of the
congestion window by monitoring the utilized bandwidth for small
changes. This method contrasts with Reno's congestion
avoidance mechanism that needs to create losses to vary the
congestion window size, Vegas attempts to predict
congestion.
Listed below are brief major implementation details: